

هل سبق لك أن واجهت موقفاً في مشروعك البرمجي حيث تحتاج إلى مساعدة ذكية في كتابة الكود، تصحيح الأخطاء، أو حتى فهم بنية مشروع معقد، لكنك تتردد في إرسال كودك الحساس إلى خدمات سحابية خارجية؟ هل تبحث عن حل يجمع بين قوة نماذج الذكاء الاصطناعي المتقدمة ومرونة التشغيل المحلي، مع الحفاظ على خصوصية بياناتك؟ إذا كانت إجابتك نعم، فأنت في المكان الصحيح. هذا المقال هو دليلك الشامل لاستكشاف Gemma 4، أحدث وأقوى عائلة من النماذج المفتوحة من Google DeepMind، وكيف يمكنك تسخير قدراتها الفائقة محلياً وعبر واجهة برمجة التطبيقات (API)، وحتى دمجها كوكيل ذكي في بيئة تطويرك مثل OpenCode.
ما هو Gemma 4؟
Gemma 4 هي عائلة من النماذج اللغوية الكبيرة (Large Language Models – LLMs) مفتوحة المصدر (Open-Source) من تطوير Google DeepMind [1]. تم تصميم هذه النماذج لتكون الأكثر قدرة في فئتها، مع التركيز على الاستدلال المتقدم (Advanced Reasoning) وسير العمل الوكيل (Agentic Workflows). تتميز Gemma 4 بقدرتها على معالجة النصوص والصور، وتدعم بعض إصداراتها الأصغر معالجة الصوت أيضاً، مما يجعلها نماذج متعددة الوسائط (Multimodal). تتوفر Gemma 4 بأحجام مختلفة (E2B, E4B, 26B MoE, 31B Dense) لتناسب سيناريوهات النشر المتنوعة، من الأجهزة الطرفية (Edge Devices) مثل الهواتف وأجهزة Raspberry Pi إلى محطات العمل القوية [2].
لماذا تهتم بـ Gemma 4؟
في عالم تطوير البرمجيات سريع التطور، يواجه المطورون تحديات مستمرة تتطلب حلولاً ذكية وفعالة. نماذج الذكاء الاصطناعي التوليدية أصبحت أداة لا غنى عنها، لكن الاعتماد الكلي على الخدمات السحابية قد يثير مخاوف تتعلق بـ:
- الخصوصية والأمان (Privacy and Security): إرسال الكود المصدري أو البيانات الحساسة إلى خوادم خارجية قد يشكل خطراً أمنياً.
- التكلفة (Cost): الاستخدام المكثف لواجهات برمجة التطبيقات السحابية يمكن أن يكون باهظ الثمن.
- الاعتمادية (Reliability): قد تتأثر الإنتاجية بانقطاع الاتصال بالإنترنت أو قيود الخدمة.
- التخصيص (Customization): صعوبة تعديل النماذج السحابية لتناسب احتياجات مشروعك الفريدة.
هنا يأتي دور Gemma 4 كحل جذري. بفضل طبيعتها مفتوحة المصدر وقدرتها على التشغيل المحلي، تمنحك Gemma 4:
- التحكم الكامل (Full Control): يمكنك تشغيل النموذج على جهازك الخاص، مما يضمن بقاء بياناتك وكودك في بيئتك الآمنة.
- المرونة (Flexibility): إمكانية التعديل والتحسين (Fine-tuning) للنموذج ليناسب مهامك المحددة.
- الاستقلالية (Independence): العمل دون الحاجة لاتصال دائم بالإنترنت (في حالة التشغيل المحلي).
- القدرات المتقدمة (Advanced Capabilities): تدعم Gemma 4 ميزات مثل استدعاء الدوال (Function Calling)، توليد الكود (Code Generation)، والاستدلال متعدد الخطوات (Multi-step Reasoning)، مما يجعلها مثالية لبناء وكلاء AI متقدمين [1].
كيف تبدأ؟
يمكنك التفاعل مع Gemma 4 بطريقتين رئيسيتين: التشغيل محلياً على جهازك، أو استخدامها عبر واجهة برمجة التطبيقات (API) السحابية.
استخدام Gemma 4 محلياً (مع Ollama)
يُعد Ollama أداة ممتازة لتشغيل النماذج اللغوية الكبيرة محلياً بسهولة. ستحتاج إلى تثبيت Ollama ثم سحب نموذج Gemma 4.
متطلبات الجهاز للتشغيل المحلي:
لتحقيق أفضل أداء، خاصة مع النماذج الأكبر من Gemma 4، يوصى بمتطلبات جهاز معينة. على سبيل المثال، لتشغيل نموذج Gemma 4 8B بكفاءة، ستحتاج إلى:
- نظام التشغيل: macOS (مع Apple Silicon M1/M2/M3/M4/M5) أو Linux أو Windows.
- الذاكرة الموحدة (Unified Memory) / ذاكرة الوصول العشوائي (RAM): 16 جيجابايت على الأقل. نموذج Gemma 4 8B يستهلك حوالي 9.6 جيجابايت عند التحميل [4].
- وحدة معالجة الرسوميات (GPU): يفضل وجود GPU قوي للاستفادة من تسريع الاستدلال (Inference Acceleration). تدعم Ollama تسريع GPU على Apple Silicon (باستخدام MLX Framework) وعلى أنظمة Linux/Windows مع NVIDIA GPUs.
خطوات الإعداد:
- تثبيت Ollama:
إذا كنت تستخدم macOS، يمكنك تثبيته عبر Homebrew:brew install --cask ollama-appبعد التثبيت، تأكد من تشغيل Ollama. على macOS، يمكنك فتح التطبيق من مجلد التطبيقات. يمكنك التحقق من أن الخادم يعمل باستخدام الأمر التالي في الطرفية:ollama list - سحب نموذج Gemma 4:
بعد تثبيت Ollama وتشغيله، يمكنك سحب نموذج Gemma 4 (الإصدار الافتراضي 8B) باستخدام الأمر:ollama pull gemma4سيقوم هذا الأمر بتنزيل النموذج، والذي يبلغ حجمه حوالي 9.6 جيجابايت. يمكنك التحقق من تنزيله باستخدام:ollama list - اختبار النموذج محلياً:
يمكنك التفاعل مع النموذج مباشرة من الطرفية:bash ollama run gemma4:latest "Hello, what model are you?"
هذا الأمر سيشغل النموذج ويسمح لك بالتفاعل معه مباشرة في الطرفية. يمكنك طرح الأسئلة والحصول على إجابات من Gemma 4. `
استخدام Gemma 4 عبر API (Google AI Studio/Vertex AI)
إذا كنت تفضل الاستفادة من قوة Gemma 4 دون الحاجة لإدارة البنية التحتية المحلية، يمكنك استخدامها عبر واجهة برمجة التطبيقات (API) من خلال Google AI Studio أو Vertex AI [3].
الحصول على مفتاح API:
- Google AI Studio: توجه إلى Google AI Studio وقم بتسجيل الدخول باستخدام حساب Google الخاص بك. يمكنك إنشاء مفتاح API جديد هناك [5].
- Vertex AI: إذا كنت تعمل ضمن بيئة Google Cloud، يمكنك الحصول على مفتاح API من خلال Vertex AI، والذي يوفر تحكماً أكبر في الموارد والتخصيص [6].
مثال كود Python لاستخدام Gemma 4 عبر API (باستخدام مكتبة transformers):
يمكنك استخدام مكتبة transformers من Hugging Face للتفاعل مع Gemma 4. تأكد من تثبيت المكتبات المطلوبة:
pip install -U transformers torch accelerateثم استخدم الكود التالي:
import torch
from transformers import AutoProcessor, AutoModelForCausalLM
MODEL_ID = "google/gemma-4-E2B-it" # أو أي نموذج Gemma 4 آخر
# تحميل النموذج
processor = AutoProcessor.from_pretrained(MODEL_ID)
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
dtype=torch.bfloat16,
device_map="auto"
)
# إعداد الرسائل
messages = [
{"role": "system", "content": "أنت مساعد مفيد."},
{"role": "user", "content": "اكتب نكتة قصيرة عن توفير ذاكرة الوصول العشوائي."},
]
# معالجة الإدخال
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
inputs = processor(text=text, return_tensors="pt").to(model.device)
input_len = inputs["input_ids"].shape[-1]
# توليد الإخراج
outputs = model.generate(**inputs, max_new_tokens=1024)
response = processor.decode(outputs[0][input_len:], skip_special_tokens=False)
# طباعة الاستجابة
print(response)يشرح هذا الكود كيفية تحميل نموذج Gemma 4 باستخدام مكتبة transformers، ثم إعداد محادثة بسيطة مع النموذج. يتم تمرير الرسائل إلى النموذج، ويتم توليد استجابة يتم طباعتها في النهاية. لاحظ أن MODEL_ID يمكن تغييره ليتناسب مع النموذج الذي ترغب في استخدامه. `
مثال تطبيقي كامل: دمج Gemma 4 كوكيل في OpenCode
OpenCode هو مساعد برمجة يعتمد على الطرفية (Terminal-based coding assistant) ويوجد منه اصدار يدعوم واجهة رسومية لمن لا يحب الطرفية ، ويمكنه التحدث إلى أي API متوافق مع OpenAI. يمكنك دمج Gemma 4 معه، إما محلياً عبر Ollama أو باستخدام مفتاح API سحابي، لتحويله إلى وكيل AI قوي يساعدك في مهام البرمجة [4].
إعداد OpenCode:
تأكد من تثبيت OpenCode على جهازك. يمكنك زيارة opencode.ai للحصول على تعليمات التثبيت أو تثبيته عبر مدير الحزم الخاص بك.
تكوين Ollama و Gemma 4 مع OpenCode (للتشغيل المحلي):
لدمج Gemma 4 محلياً مع OpenCode عبر Ollama، ستحتاج إلى تعديل ملف إعدادات OpenCode. عادةً ما يكون هذا الملف موجوداً في ~/.config/opencode/opencode.jsonc.
- إضافة Ollama كمزود (Provider) مخصص:
أضف الإعدادات التالية إلى ملفopencode.jsonc:{ "provider": { "ollama": { "npm": "@ai-sdk/openai-compatible", "options": { "baseURL": "http://localhost:11434/v1" }, "models": { "gemma4:latest": {} } } } }يحدد هذا التكوين Ollama كمزود جديد لـ OpenCode، ويشير إلى عنوان URL الأساسي لخادم Ollama المحلي. كما يحدد نموذجgemma4:latestكنموذج متاح للاستخدام. ` - إضافة إدخال مصادقة وهمي (Placeholder Authentication):
على الرغم من أن Ollama يعمل محلياً ولا يتطلب مفتاح API، إلا أن OpenCode يتوقع وجود إدخال مصادقة. أضف ما يلي إلى ملف~/.local/share/opencode/auth.json:{ "ollama": { "type": "api", "key": "ollama" } }هذا الإدخال يوفر مفتاح API وهمي لـ Ollama، مما يرضي متطلبات OpenCode للمصادقة دون الحاجة إلى مفتاح حقيقي. ` - إعادة تشغيل OpenCode:
بعد تعديل ملفات الإعدادات، أعد تشغيل OpenCode لتطبيق التغييرات. - تحديد Gemma 4 كنموذج:
داخل OpenCode، يمكنك استخدام الأمر/modelsللتبديل إلىollama/gemma4:latest.
تكوين Gemma 4 مع OpenCode (باستخدام API سحابي):
إذا كنت تستخدم مفتاح API من Google AI Studio أو Vertex AI، يمكنك تكوين OpenCode لاستخدامه كالتالي:
- إضافة مزود (Provider) جديد (مثلاً
google-ai-studio):
أضف الإعدادات التالية إلى ملفopencode.jsonc:{ "provider": { "google-ai-studio": { "npm": "@ai-sdk/google", "options": { "baseURL": "https://generativelanguage.googleapis.com/v1beta" }, "models": { "gemma-4": {} } } } }هذا التكوين يضيف مزوداً جديداً لـ Google AI Studio، مع تحديد عنوان URL الأساسي لنقطة نهاية API ونموذجgemma-4. ` - إضافة مفتاح API الخاص بك:
أضف مفتاح API الذي حصلت عليه من Google AI Studio إلى ملف~/.local/share/opencode/auth.json:{ "google-ai-studio": { "type": "api", "key": "YOUR_GOOGLE_AI_STUDIO_API_KEY" } }استبدلYOUR_GOOGLE_AI_STUDIO_API_KEYبمفتاح API الفعلي الخاص بك. ` - إعادة تشغيل OpenCode وتحديد النموذج:
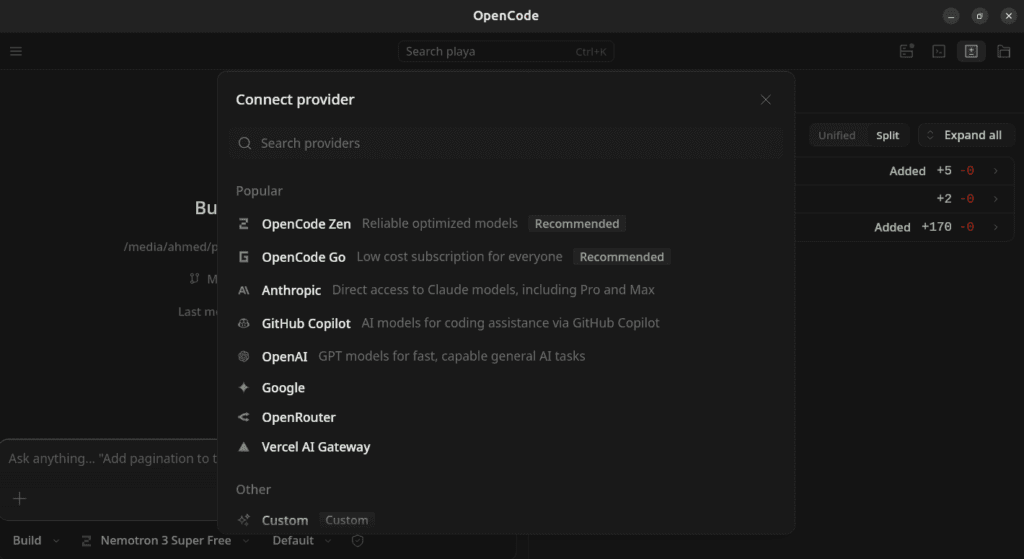
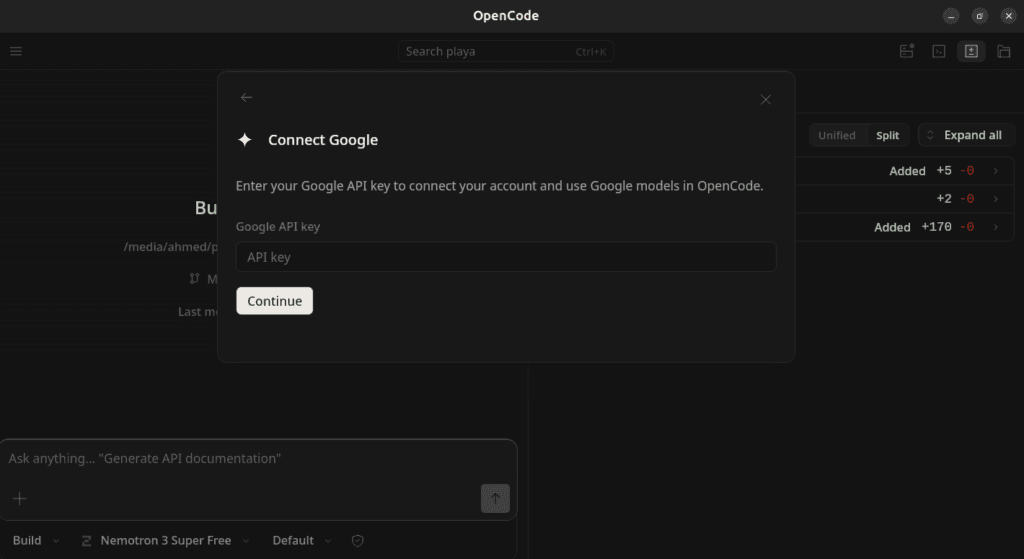
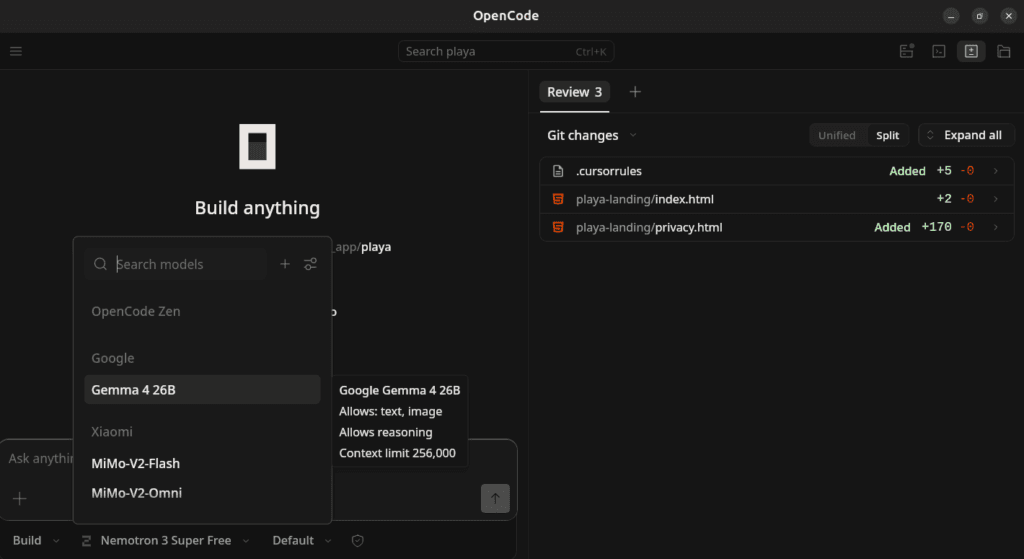
أعد تشغيل OpenCode، ثم استخدم الأمر/modelsللتبديل إلىgoogle-ai-studio/gemma-4. - من بيئة OpenCode الرسومية يمكن اضافة
gemma-4بكل سهولة عن طريق إختيار مزود (Connect Provider ) و اختيار google ثم وضع مفتاح Api الخاص بجوجل و بعدها اختيار نمود gemma 4
مثال على الاستخدام في OpenCode:
بعد الإعداد، يمكنك البدء في استخدام Gemma 4 كوكيل AI في OpenCode. على سبيل المثال، يمكنك أن تطلب منه:
- شرح الكود:
explain this function: <function_name> - توليد الكود:
generate a Python function to calculate factorial - تصحيح الأخطاء:
fix the bug in this JavaScript code: <code_snippet> - المساعدة في أوامر Shell:
how to find files older than 7 days in Linux
نصائح ومزالق يجب تجنبها
- إدارة الذاكرة (Memory Management): عند التشغيل المحلي، راقب استهلاك الذاكرة. النماذج الكبيرة تستهلك الكثير من RAM/Unified Memory. أغلق التطبيقات غير الضرورية لتحرير الذاكرة [4].
- حجم السياق (Context Window): على الرغم من أن Gemma 4 تدعم نوافذ سياق كبيرة (تصل إلى 256K توكن)، إلا أن الأجهزة ذات الذاكرة المحدودة (مثل 16 جيجابايت) قد تواجه تدهوراً في الأداء مع المدخلات الطويلة جداً. حاول إبقاء المدخلات أقل من 32K توكن للحصول على أفضل النتائج على الأجهزة الأقل قوة [4].
- تحديث Ollama: تأكد دائماً من استخدام أحدث إصدار من Ollama للاستفادة من التحسينات في الأداء وتسريع GPU [4].
- المهام المعقدة متعددة الملفات: بينما تتفوق Gemma 4 في المهام الفردية وتوليد الكود، قد تواجه صعوبة في المهام التي تتطلب تخطيطاً عبر ملفات متعددة أو إعادة هيكلة كبيرة للمشروع. في هذه الحالات، قد يكون التبديل إلى نماذج سحابية أقوى (مثل Claude Opus أو GPT-5) (إذا كنت تستخدم OpenCode) خياراً أفضل [4].
- الخصوصية: إذا كانت خصوصية الكود هي أولويتك القصوى، التزم بالتشغيل المحلي عبر Ollama. استخدام API سحابي يعني أن كودك سيمر عبر خوادم طرف ثالث.
الخلاصة :
Gemma 4 هي إضافة قوية ومثيرة للإعجاب لعالم النماذج اللغوية المفتوحة. أرى أنها تستحق التجربة لكل مطور يبحث عن حلول AI ذكية ومرنة. قدرتها على التشغيل المحلي تجعلها خياراً ممتازاً للمشاريع التي تتطلب خصوصية عالية أو بيئات عمل غير متصلة بالإنترنت. كما أن دعمها لسير العمل الوكيل وتوليد الكود يجعلها أداة قيمة لزيادة الإنتاجية.
متى تستخدمها؟ استخدم Gemma 4 للمساعدة في مهام البرمجة اليومية، شرح الكود، توليد الأجزاء النمطية (Boilerplate Code)، والمساعدة في أوامر Shell. هي مثالية أيضاً لبناء وكلاء AI محليين في بيئات مثل OpenCode.
متى تتجنبها؟ إذا كانت لديك مهام معقدة جداً تتطلب استدلالاً عميقاً عبر مشاريع كبيرة متعددة الملفات، أو إذا كنت بحاجة إلى أداء فائق السرعة على نطاق واسع جداً، فقد تحتاج إلى التفكير في النماذج السحابية الأكثر قوة أو نماذج Gemma 4 الأكبر حجماً التي تتطلب موارد جهاز أعلى.
جرب إعداد Gemma 4 محلياً مع Ollama و OpenCode اليوم. شاركنا تجربتك في التعليقات: ما هي المهام البرمجية التي ساعدتك Gemma 4 في إنجازها؟
ولا يفوتك قراءة ” OpenCode : دليلك الشامل لتحويل أفكارك البرمجية إلى كود حقيقي بلمسة ذكاء اصطناعي! “
فيديو مقدم من الاخ المهندس / عبداللطيف سعيد يقدم تجربة عملية لنموذج gemma 4
المراجع:
[1] Google Blog – Gemma 4: Our most capable open models to date: https://blog.google/innovation-and-ai/technology/developers-tools/gemma-4/[2] Google AI for Developers – Gemma 4 model card: https://ai.google.dev/gemma/docs/core/model_card_4?hl=en
[3] Google Cloud Blog – Gemma 4 available on Google Cloud: https://cloud.google.com/blog/products/ai-machine-learning/gemma-4-available-on-google-cloud
[4] haimaker.ai Blog – How to Set Up Gemma 4 with OpenCode Using Ollama (2026 Guide): https://haimaker.ai/blog/gemma-4-ollama-opencode-setup/
[5] Google AI Studio – API Key: https://aistudio.google.com/app/apikey
[6] Google Cloud – Get a Google Cloud API key: https://docs.cloud.google.com/vertex-ai/generative-ai/docs/start/api-keys



