المقدمة: عندما يغرق المبرمج في “انفجار السياق”
تخيل أنك تبني نظاماً معقداً من الوكلاء الأذكياء (Multi-Agent System) ليقوم بمهمة برمجية ضخمة. في البداية، كل شيء يسير على ما يرام، ولكن مع مرور الوقت وتبادل آلاف الرسائل بين الوكلاء، تبدأ الكارثة: “انفجار السياق” (Context Explosion). يبدأ الوكلاء في نسيان الهدف الأصلي، وتصبح الاستجابات بطيئة جداً ومكلفة للغاية، فيما يعرف بـ “ضريبة التفكير” (Thinking Tax).
هنا يأتي دور Nemotron 3 Super، النموذج الجديد الذي أطلقته NVIDIA ليغير قواعد اللعبة. هذا النموذج ليس مجرد تحديث عادي، بل هو حل جذري لمشاكل الكفاءة والدقة التي تواجهنا كمطورين عند بناء أنظمة ذاتية التشغيل. في هذا المقال، سنغوص في أعماق هذا النموذج لنفهم لماذا يجب أن يكون جزءاً من أدواتك البرمجية اليوم.
ما هو Nemotron 3 Super؟
يعتبر Nemotron 3 Super نموذجاً لغوياً ضخماً مفتوح الأوزان، يعتمد على معمارية هجينة تجمع بين الـ Mamba والـ Transformer مع تقنية خليط الخبراء (MoE). يحتوي النموذج على 120 مليار بارامتر إجمالي، ولكن بفضل تقنية MoE، يتم تفعيل 12 مليار بارامتر فقط لكل “توكن”، مما يمنحه توازناً مذهلاً بين الذكاء الخارق وسرعة التنفيذ.
السر في المعمارية: هجين Mamba-Transformer
لماذا اختارت NVIDIA هذا المزيج؟ الإجابة تكمن في نقاط القوة لكل معمارية:
- Mamba-2 للكفاءة الخطية: على عكس الـ Transformer التقليدي الذي تزداد تكلفته بشكل تربيعي مع طول النص، توفر طبقات Mamba-2 معالجة سريعة جداً للنصوص الطويلة. هذا ما يجعل نافذة السياق التي تصل إلى 1 مليون توكن حقيقة واقعة وليست مجرد رقم تسويقي.
- Transformer للدقة المتناهية: طبقات الـ Attention في Transformer تتدخل في أعماق محددة لضمان قدرة النموذج على استرجاع معلومات دقيقة جداً من وسط ملايين الكلمات (Needle in a Haystack).
هذا المزيج يعني أن Nemotron 3 Super يمكنه قراءة قاعدة بيانات برمجية كاملة وفهم تفاصيلها دون أن يفقد التركيز أو يستهلك موارد جهازك بشكل جنوني.
تقنية Latent MoE: ذكاء أكثر بتكلفة أقل
في نماذج MoE التقليدية، يمثل توجيه البيانات إلى “الخبراء” عنق زجاجة. قدمت NVIDIA في Nemotron 3 Super ابتكاراً يسمى Latent MoE. بدلاً من إرسال البيانات الخام، يتم ضغطها أولاً في مساحة كامنة (Latent Space) ثم توجيهها.
النتيجة؟ يمكن للنموذج استشارة 4 أضعاف عدد الخبراء المتخصصين (مثل خبير في لغة Python وآخر في SQL) بنفس التكلفة الحسابية لنموذج عادي. هذا التخصص الدقيق هو ما يجعله يتفوق في مهام الاستدلال المعقدة (Agentic Reasoning).
التنبؤ المتعدد للتوكنات (MTP): سرعة البرق في البرمجة
عادةً ما تتوقع النماذج كلمة واحدة في كل مرة، وهو نهج “قصير النظر” (Myopic) قد يؤدي إلى أخطاء منطقية في المهام الطويلة. لكن Nemotron 3 Super يستخدم تقنية Multi-token Prediction (MTP)، حيث تتوقع رؤوس تنبؤ متخصصة عدة كلمات مستقبلية في دورة واحدة (Forward Pass).
- تحسين الاستدلال العميق: إجبار النموذج على التنبؤ بالمستقبل البعيد أثناء التدريب يجعله يستوعب الهياكل المنطقية المعقدة والتبعيات طويلة المدى. هذا يظهر بوضوح في مهام “سلسلة الأفكار” (Chain-of-Thought) حيث يجب أن تتبع كل خطوة سابقتها بمنطق سليم.
- تسريع التنفيذ (Speculative Decoding): تتيح هذه التقنية ما يسمى بـ “فك التشفير التخميني” المدمج. بدلاً من الحاجة لنموذج “مسودة” (Draft Model) منفصل، يقوم النموذج نفسه بتوليد مسودات سريعة والتحقق منها، مما يسرع توليد الكود والمهام الهيكلية بنسبة تصل إلى 3 أضعاف في الوقت الفعلي.
تحسينات Blackwell وNVFP4: كفاءة الأجهزة تلتقي بذكاء البرمجيات
لا يمكن الحديث عن Nemotron 3 Super دون ذكر التحسين الفائق لمنصة NVIDIA Blackwell. تم تدريب النموذج باستخدام تنسيق NVFP4 الأصلي، وهو ابتكار يقلل بشكل كبير من متطلبات الذاكرة مع الحفاظ على الدقة.
بالمقارنة مع تنسيق FP8 التقليدي على بطاقات H100، يوفر تنسيق NVFP4 على بطاقات B200 سرعة استدلال تصل إلى 4 أضعاف. هذا يعني أنك كمطور يمكنك تشغيل نماذج أضخم وأكثر ذكاءً على موارد أقل، مما يقلل التكلفة الإجمالية للملكية (TCO) لمشاريع الذكاء الاصطناعي الخاصة بك.
التعلم المعزز (RL): نموذج تدرب في 21 بيئة مختلفة
لم تكتفِ NVIDIA بالتدريب الأولي، بل خضع Nemotron 3 Super لعملية “ما بعد التدريب” (Post-training) مكثفة باستخدام التعلم المعزز (Reinforcement Learning). تم اختبار النموذج في 21 تكويناً مختلفاً للبيئات باستخدام أدوات مثل NVIDIA NeMo Gym.
أكثر من 1.2 مليون جولة محاكاة (Environment Rollouts) ساعدت النموذج على تعلم كيفية التفاعل مع الأدوات البرمجية، وتصحيح أخطائه ذاتياً، والبقاء متوافقاً مع أهداف المستخدم حتى في المحادثات الطويلة جداً. هذا هو الفرق بين نموذج “يتحدث” ونظام “يفعل”.
الأداء العملي: سيناريوهات واقعية للمطورين
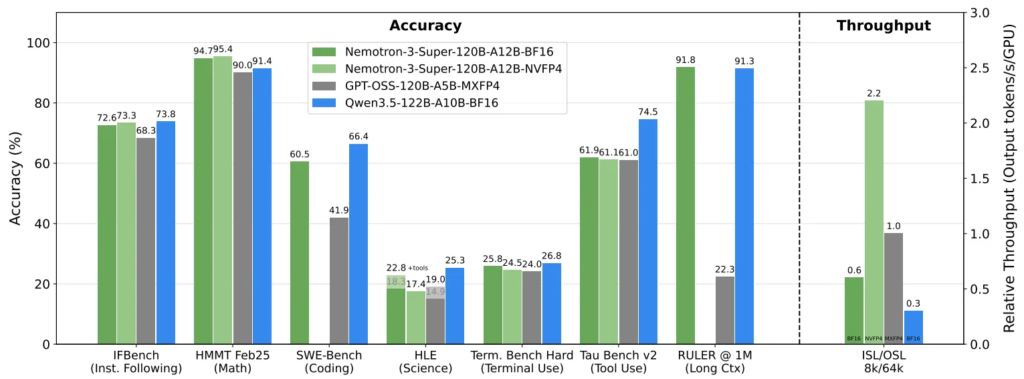
في اختبار PinchBench، وهو معيار جديد يقيس قدرة النماذج على العمل كـ “عقل” للوكلاء الأذكياء (OpenClaw Agents)، حقق Nemotron 3 Super نتيجة مذهلة بلغت 85.6%. ولكن ماذا يعني هذا لك كمطور في حياتك اليومية؟
- تطوير البرمجيات ذاتي التشغيل (Autonomous Coding):
تخيل وكيلًا يمكنه قراءة مستودع كود (Repo) يحتوي على مئات الملفات، وفهم كيفية ترابطها، ثم كتابة ميزة جديدة أو إصلاح خلل معقد دون أن يخرج عن السياق. بفضل نافذة السياق (1M Tokens)، لن تحتاج لتقنيات RAG معقدة ومكلفة في كثير من الأحيان. - تحليل الثغرات الأمنية (Cybersecurity Triaging):
يمكن للنموذج تحليل سجلات النظام (Logs) الضخمة وتتبع مسار الهجمات المحتملة عبر آلاف السطور من البيانات، وربط الأحداث ببعضها البعض بدقة متناهية، وهو أمر تعجز عنه النماذج ذات السياق المحدود. - أنظمة خدمة العملاء المتقدمة:
بدلاً من الردود الجاهزة، يمكن للوكيل المبني على Nemotron 3 Super تذكر تاريخ العميل الكامل، وتفضيلاته، والمشاكل السابقة التي واجهها، ليقدم حلاً مخصصاً تماماً وكأنه موظف بشري خبير.
دليل عملي: كيف تبدأ باستخدام Nemotron 3 Super؟
أفضل طريقة لتجربة النموذج هي عبر NVIDIA NIM، والتي توفر واجهة برمجية متوافقة مع OpenAI، مما يسهل دمجها في مشاريعك الحالية.
مثال برمجى باستخدام Python:
إليك كيف يمكنك استدعاء النموذج للقيام بمهمة استدلال معقدة:
from openai import OpenAI
# احصل على مفتاح API الخاص بك من build.nvidia.com
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = "$NVIDIA_API_KEY"
)
completion = client.chat.completions.create(
model="nvidia/nemotron-3-super-120b-a12b",
messages=[{"role":"user","content":"قم بتحليل هذا الكود البرمجي واقترح تحسينات للأداء مع مراعاة معايير الأمان:"}],
temperature=0.5,
top_p=1,
max_tokens=1024,
stream=True
)
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")شرح الكود:
نستخدم مكتبة openai للاتصال بـ base_url الخاص بـ NVIDIA. لاحظ أننا نستخدم النموذج nemotron-3-super-120b-a12b. بفضل معمارية MoE، ستحصل على استجابة سريعة جداً رغم ضخامة النموذج.
كما يمكنك ان تجده بسهوله في Opencode او Kilo Code او Ollama بمجرد البحث عنه ستجده اختره و قم بتجربته .
رأي شخصي: هل هو “Super” حقاً؟
بعد تحليل المعمارية والنتائج، أرى أن Nemotron 3 Super هو النموذج الذي كنا ننتظره لبناء وكلاء أذكياء حقيقيين. مشكلة “ضريبة التفكير” كانت العائق الأكبر أمام تحويل الوكلاء من مجرد “ألعاب” إلى أدوات إنتاجية. بفضل تحسينات NVIDIA في معمارية Blackwell ودعم NVFP4، أصبح تشغيل نموذج بهذا الحجم أمراً ممكناً وبكفاءة عالية.
نصيحتي لك: إذا كان مشروعك يعتمد على معالجة سياقات طويلة (أكثر من 100 ألف توكن) أو يتطلب استدلالاً منطقياً دقيقاً في البرمجة، فلا تتردد في تجربة هذا النموذج.
الخاتمة :
لقد وضعت NVIDIA معياراً جديداً للنماذج المفتوحة الموجهة للوكلاء الأذكياء. Nemotron 3 Super ليس مجرد نموذج لغوي، بل هو محرك استدلال متكامل مصمم للمستقبل.
ماذا تنتظر؟ قم بزيارة build.nvidia.com الآن، واحصل على مفتاح API مجاني لتجربة النموذج في مشروعك القادم. شاركنا تجربتك في التعليقات: هل تعتقد أن المعماريات الهجينة هي مستقبل الذكاء الاصطناعي؟
لا يفوتك قراءة :